[NLP] 자연어 처리 개요
🎯NLP(Natural Language Processing : 자연어 처리)란?
(컴퓨터를 활용하여) 인간이 일상적으로 사용하는 언어를 처리 및 분석하는 기술로
인공지능의 한 분야로서 머신러닝을 사용하여 텍스트와 데이터를 처리하고 해석하는 것을 의미한다.
- 자연어 처리의 대표적인 유형으로는 자연어 인식 및 자연어 생성이 있다.
- 자연어 이해 및 생성에 활용할 수 있는적합한 계산 모델에 대한 연구
자연어 처리의 응용
- 정보검색 : 키워드검출, 문서 유사도 측정, 문서 랭킹
ex) Google, Yahoo, Naver
- 질의응답 : 음성인식,의미분석,정보추출
ex) IBM Watson, Apple Siri
- 기계 번역
ex) 한영/영한, 일한/한일, 중한/한중
- 맞춤법 검사
ex) 철자교정, 문법 교정
- 감성분석
- 소셜 미디어 분석
🎯 비정형 데이터
| 정형 데이터 | 비정형 데이터 | |
| 정의 | 사전에 잘 정의된 구조를 따르는 데이터 | 구조가 없고, 모호한, 이질적(heterogenous) 데이터 |
| 데이터의 특성 | 양적 데이터 | 질적 데이터 |
| 데이터 모델 | 모델이 정의되고 일부 데이터가 저장된 후에는모델을 변경하기 어려움 | 특정 스키마가 포함되지 않으므로, 상대적으로더 유연 |
| 데이터 포맷 | 제한된 수의 데이터 포맷 사용 가능 | 매우 다양한 데이터 포맷 사용 가능 |
| 데이터베이스 | SQL 기반 관계형 데이터베이스가 사용 | 특정 스키마가 없는 NoSQL 데이터베이스가 사용 |
| 검색 | 데이터를 검색하고 찾기가 매우 쉬움 | 특정 데이터 검색이 매우 어려움 |
| 분석 | 데이터의 양적 특성으로 인해 분석이 매우 쉬움 | 기존 소프트웨어 도구로는 분석이 어려움 |
| 저장 방법 | 데이터 웨어하우스 | 데이터 레이크 |
비정형 데이터의 주요 특성
- 디지털 데이터로서 예측 불가능
- 상시 생성되며 항상 이동 중에 있음
- 혼합, 다중 모드 및 상호 운용 가능
- 지리적으로 분산되어 더 나은 보호 수단 제공
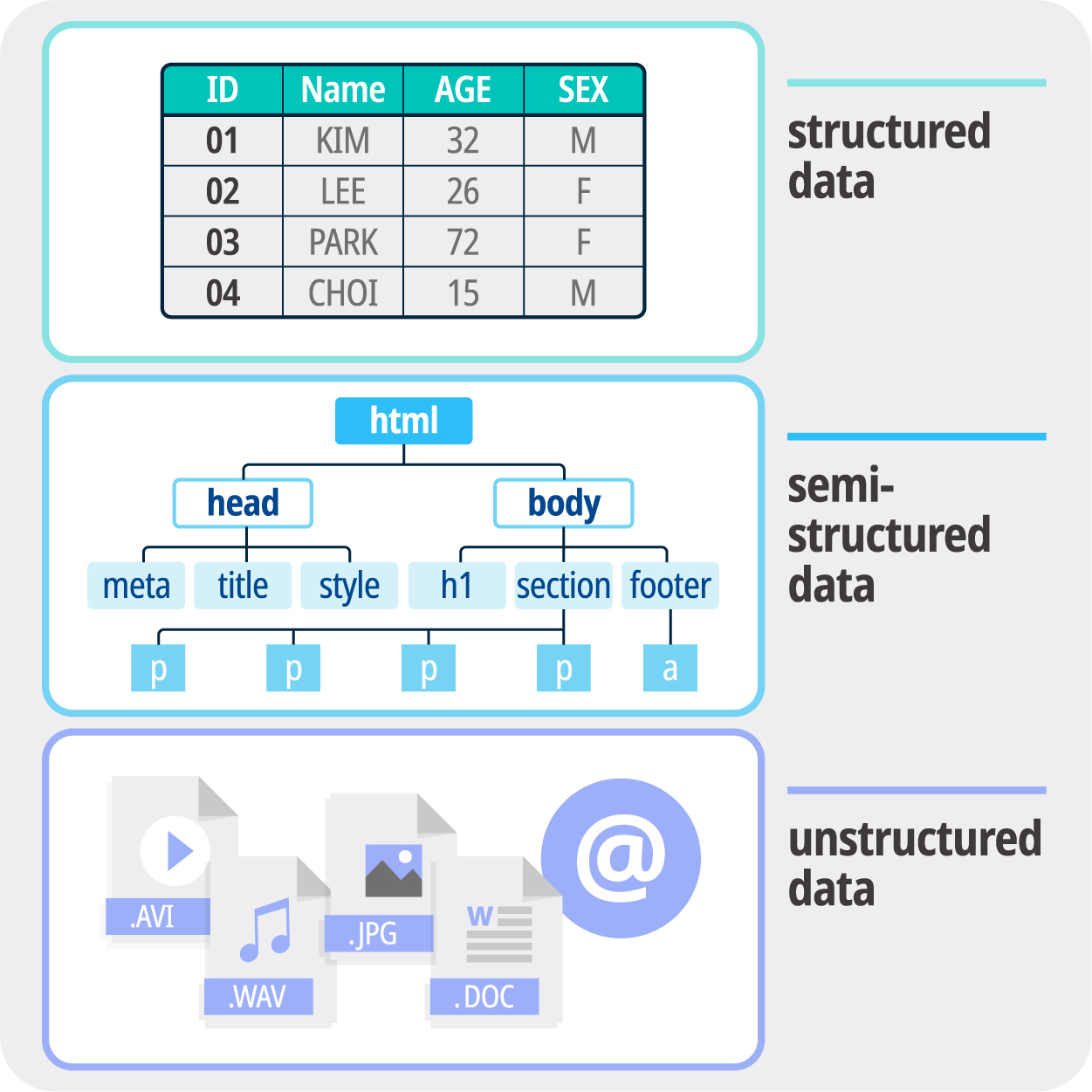
비정형 데이터의 분석 과정

1) 비정형 데이터의 내용 파악과 비정형 데이터 속 패턴(pattern) 발견을 위해 데이터 마이닝, 텍스트 분석, 비표준 텍스트 분석 등과 같은 다양한 기법을 사용한다.
2) 비정형 데이터의 정련 과정을 통해 정형 데이터로 만든 후, 분류, 군집화, 회귀분석, 요약, 이상감지 분석 등의 데이터 마이닝을 통해 의미있는 정보를 발굴한다.
3) 정제된 데이터베이스를 기반으로 일정한 기준이 적용된 상식적 범위에서 부분적인 데이터를 다루는 정형 데이터 마이닝의 한계를 뛰어넘는 기법이 존재한다. ex) 텍스트 마이닝, 웹 마이닝, 오피니언 마이닝, 소셜 마이닝
텍스트 마이닝
- 인간의 언어로 이루어진 비정형 텍스트 데이터들을 자연어 처리(Natural Language Processing)방식을 이용하여 대규모 문서에서 정보 추출, 연계성 파악, 분류 및 군집화,요약 등을 통해 데이터에 숨겨진 의미를 발견하는 기법
- 일반적으로 입력 텍스트를 정형화한 다음, 정형화 데이터 내에서 패턴을 추출하고 난 후, 출력을 평가하고 번역하는 과정을 포함
- 텍스트 마이닝의 목적은 비정형 데이터나 정형 데이터, 반정형 데이터를 처리하여 의사결정을 위해 필요한 고차원적이고 의미 있는 정보나 지식을 추출하는 것
- 입력 -> 처리(준비 -> 전처리 -> 지식추출) -> 출력
- 준비 : 입력되는 여러 가지 텍스트 문서의 데이터들을 문제 범위에 적절한 것으로 확립
- 전처리 : 조직화된 텍스트들을 정형화된 표현 양식으로 만듦
웹 마이닝
- 데이터마이닝 기술의 응용분야로서 인터넷을 통해 웹 서비스를 이용하면서 웹에서 패턴을 발견하는 것
- 데이터의 속성이 반정형이거나 비정형이고, 링크(Link) 구조를 가지고 있기 때문에 전통적인 데이터마이닝 기술에 추가적인 분석기법이 필요
- 웹 콘텐츠 마이닝 : 웹 페이지에서 유용한 데이터, 정보, 지식을 마이닝하고 추출하고 통합하는 것
- 웹 사용 마이닝 : 웹 사이의 연결 분석, 웹 사이트의 노드와 연결 구조를 분석하기 위해 그래프 이론을 사용하는 과정
오피니언 마이닝
- 어떤 사안이나 인물, 이슈, 이벤트 등과 관련 원천 데이터에서 의견이나 평가, 태도, 감정 등과 같은 주관적인 정보를 식별하고 추출하는 것
- 문서, 문장, 특징, 관점 수준에서 표현된 견해가 긍정적인지, 부정적인지, 중립적인지, 진보적인지 주어진 텍스트의 특성을 분류하는 것
- ex) 온라인 쇼핑몰에서 잠재 구매자의 상품평 검색효율을 높이기 위해 상풍평 데이터에 선위를 결정하는데 이용
- ex) 영화 관란 후기 요악, 긍정/부정 평가
소셜 마이닝
- 소셜 미디어 분석에서 언어 분석 기술을 적용해 검색어에 대한 기간별 소셜 모니터링, 연관어 탐색, 감성 분석 서비스 등을 제공
- 다음 소프트의 경우 소셜 매트릭스 서비스 제공
🎯 NLP의 단계적 처리
- 언어학에 기반해 단계적인 처리를 수행


1) Phonetics, Phonology (음성학, 음운론) - SOUNDS

2) Words - 단어
ex) This is a simple sentence
- * 토큰(token) : 더 나눌 수 없는 언어요소
- 단어 토큰화 : 띄어쓰기를 기준으로 분석
- 영어의 경우 보통 띄어쓰기로 토큰이 구분되지만, 한글의 경우 띄어쓰기 만으로 토근을 구분하기는 어렵다.
- Language Model : 문장이 얼마나 자연스러운지 확률적으로 계산함으로써 문장 내 특정 위치에 출현하기에 적합한 단어를 확률적으로 예측하는 모델 -> 앞서 나온 단어를 기반으로 뒤에 어떤 단어가 등장해야 문장이 자연스러운지 판단하는 도구
- Spelling correction : 맞춤법 수정 모델

3) Morphology - 형태소
- 형태소(morpheme) : 의미를 가지는 최소 단위 단어로서 더 이상 두 개 이상의 의미를 가지는 단어로 나눌 수 없는 말
- 토큰화(tokenization) : 문장이나 문서 등(Corpus)을 형태소로 구분하는 과정
- 텍스트 마이닝에서 형태소 분석은 형태소 자체를 분석하는 것이 아니라 텍스트를 형태소로 구분하여 분석하는 것을 의미
- 한글의 경우 '대명사 + 조사' 와 같이 두 개 이상의 형태소가 포함된 경우가 많아 다른 언어에 비해 상대적으로 번거롭다.
- 불용어 (stop words) : 토큰화 된 단어들 중 자주 사용되지만, 의미없이 관성적으로 사용되는 단어. ex) 조사, 대명사 ... -> 제거 필요
- Lemmatization(표제어 추출) : 형태가 다르지만 뿌리가 같은 단어를 찾아 가는 과정
ex) am, are, is -> be
- 표제어 추출 방법으로는 단어의 형태학적 파싱을 통해 어간(stem)과 접사(affix)를 분리하는 것이다.
- 이 떄, 어간은 단어의 의미를 담고 있는 핵심 부분을 말하며, 접사는 추가적인 의미를 주는 부분을 말한다.

4) Part of Speech (POS) - 품사
| 영어 8품사 | 명사(Noun) / 동사(Verb) / 대명사(Pronoun) / 부사(Adverb) / 접속사(Conjuntion) / 감탄사(Interjection) / 형용사(Adjective) / 전치사(Preposition) |
| 한글 9품사 | 명사 / 대명사 / 수사 / 동사 / 형용사 / 관형사 / 부사 / 조사 / 감탄사 |
- (POS tagging) 품사 태깅 : 각 단어에 품사를 붙이는 절차로 실용적인 작업 전 반드시 해야하는 사전 단계이다.
- 품사 태깅을 하기 위해서는 어떤 품사체계를 사용할지 결정해야한다. (크게 / 세부적으로)
- 품사를 알면 단어의 중의성을 해소할 수 있고, 중요한 정보를 추출할 수 있다.
품사 태깅의 두 가지 방법
- 규칙 기반의 태거 (Rule-based taggers)
- 통계적 태거 (Stochastic taggers)

5) Syntax - 구문 분석
- Syntax : 문법, 구조, 또는 언어 문장 내에 있는 구성요소의 순서를 의미
- 구문 분석에서는 문장이 구조적으로 옳은지를 판단 (Syntatic Parshing)
- 구조적 중의성을 가지는 단점이 존재
- 즉, 문장이 문법적으로 옳은가를 판단

- The dog bit the boy. (O)
- The boy bit the dog. (O). //소년이 강아지를 문다. 의미적으로는 이상하지만 문법적으로는 맞는 문장
- Bit boy dog the the. (X)
- 구문 분석의 결과로 생기는 트리는 입력된 모든 문장의 단어들을 커버해야하며, 입력되지 않은 단어를 끼워서는 안된다.
- 트리는 가장 상위에 시작 노드 S(sentence)를 가지고 있어야 한다.

6) Semantics - 의미 분석
- 의미 분석은 해당 문장이 의미적으로 옳은 문장인지를 분석하는 과정
ex) 사람이 비행기를 먹는다 -> 구조적으로는 옳지만 의미적으로는 틀린 문장
- 의미 분석 단계에서 동형이의어, 동음이의어, 다의어의 의미를 정확히 파악해 문장 전체의 의미를 이해하게 된다.
- 구문 분석의 결과를 보충
- Named entity recognition (NER)
- 문자열 내에서 기관명, 인믈, 장소뿐만 아니라 화폐, 시간 퍼센티지 표현까지 포괄하는 NE를 인식하는 작업
- 즉, 문자열 안에서 NE의 위치를 알아내고, 사전 정의한 카테고리에 따라 알맞게 분류하는 작업을 의미
ex) Michael Jdffery Jordan was born in Brooklyn, New York. 이라는 문장안에서
Michael Jdffery Jordan was born in Brooklyn, New York.
NE는 다음과 같이 3가지이다.
- Word sense disambiguation (WSD)
- 단어 의미 중의성 해소를 의미
- 문맥에서의 단어 토큰을 조사하고, 사용되는 각각의 단어의 의미를 결정하는 작업
- 사전 자료나 지식 기반 데이터베이스를 필요로 하며, 지식 기반 방법(Knowledge-based approach)과 지도 학습 방법(Supervised approach)를 사용
- Semantic role labeling (SRL)
- 의미역 결정이란 문장 성분의 의미역을 결정하는 것을 말한다.
- 의미역 : 명사구가 서술어와 관련하여 지니는 의미 기능
- 문장의 각 성분이 다른 구조로 배열된다 하더라도 같은 의미역을 가질 수 있고, 같은 구조로 배열된 구문이 다른 의미역을 지닐 수도 있다.
7) Discourse
- 각 문장의 의미는 앞선 문장에 의해 영향을 받고 다음 문장에 영향을 미친다.
- 문장에 포함된 존재들은 명확히 규정되어 있어야 하고 이전의 존재와 관련되어 있어야한다.
- 즉, 전체적인 discourse (이야기, 담화)는 긴밀히 밀착되어 있어야 한다.
NLP가 어려움 이유
- 언어가 가진 근본적인 활용법 ex) 문법, 구문 등
- 언어를 활용하는 주체의 자유로움 ex) 사회적 언어의 진화
- 띄어쓰기에 대한 허용
- 시적 허용
- 줄임말 / 구어/ 신조어
🎯 NLP의 문제점
1. 모호성
- 언어가 가진 해석(interpretation)의 어려움 : 모호성 (Ambiguity)

- 언어가 가진 인식 (recognition)의 어려움 : 음성학(Phonetics) 관련 문제

2. Scale
- 대용량의 데이터
- Statistical NLP : 대규모 데이터를 통한 (기계)학습 => 시간 단축 가능

- 특정 현상/활용에 대한 적정량의 (대규모) 데이터의 수집이 필요
3. Sparsity (희소)
- 특정 정보에 편중된 분포
- Zipf's law : 지프의 법칙에 따르면 어떠한 자연어 말뭉치 표현에 나타나는 단어들을 그 사용 빈도가 높은 순서대로 나열하였을 때, 모든 단어의 사용 빈도는 해당 단어의 순위에 반비례한다. 따라서 가장 사용 빈도가 높은 단어는 두 번째 단어보다 빈도가 약 두 배 높으며, 세 번째 단어보다는 빈도가 세 배 높다.

4. Variation
- 문장의 변형에 강건한 POS tagger 를 만들기 어렵다.



5. Expressivity
- 언어의 자유로운 활용은 모호함에도 영향을 주지만, 표현력에도 영향을 미친다.
- 같은 의미를 표현하는 다양한 표현이 존재

6. 한국어의 어려움
- 모호성 (표현의 중의성)
ex) 차를 마시러 공원에 가는 차 안에서 나는 그녀에게 차였다.
- 문장 내 정보 부족
- 언어는 효율성 극대화를 위해 대화 과정에서 정보를 생략하기도 한다.
ex) 나는 철수를 때리지 않았다. -> 철수 말고 다른 애를 때렸다.
-> 아무도 때리지 않았다.
- Paraphrase
- 같은 의미의 문장을 각기 다른 표현 방식으로 표현하는 것이 다양하다.
- 교착어 : 어간에 접사가 붙어, 단어를 이루고 의미와 문법적 기능이 정해짐
- 접사 추가에 따른 의미 발생
ex) 사과(어간) + 를(접사) -> 사과는 목적어에 해당
사과(어간) + 가(접사) -> 사과는 주어가 된다.
- 유연한 단어 순서
ex) 나는 밥을 먹으러 간다. = 나는 간다, 밥을 먹으러 = 밥을 먹으러 나는 간다. ....
이처럼 한국어는 단어의 순서를 바꾸어도 맥락을 이해하는데 문제가 없다.
- 모호한 띄어쓰기 규칙
: 맞춤법 상 띄어쓰기 규칙이 정해져 있기는 하나, 띄어쓰기를 지키지 않아도 문장의 맥락을 이해하는데 큰 무리가 없는 언어이다. 하지만 사람들이 띄어쓰기를 지키지 않고 뭉텅이로 작성한 텍스트를 컴퓨터가 정확하게 인식하는 것이 어렵다.
- 평서문과 의문문의 차이가 없다. (주어 부재)
| 영어 | I had lunch. | Did you have lunch? |
| 한국어 | 점심 먹었어. | 점심 먹었어? |
🎯 NLP의 응용
1. 기계 번역 (Maxhine translation)
2. 언어 생성 (Language generation)
3. 인공지능
🎯 관련 분야
1. 정보 검색 (Information retrieval)

- 정보 검색 (Information retrieval) : 컨텍스트 기반 인덱싱 또는 메타데이터의 도움을 받아 사용자가 제공한 특정 쿼리를 기반으로 텍스트에서 가장 적절한 정보를 액세스하고 검색하는 프로세스
- 구글 검색은 정보 검색의 가장 유명한 예이다.
- 이러한 정보 검색 시스템은 사용자가 필요한 정보를 찾는 데 도움을 주지만, 답을 추론하거나 생성하려고 시도하지는 않는다.
- 사용자에게 제공되는 필수 정보로 구성될 수 있는 문서의 존재와 위치에 대해 제공할 뿐이다.

- 위의 도표에서 볼수 있듯 IR 시스템은 필요한 정보에 대한 관련 출력을 문서 형태로 검색하여 출력물을 반환한다.
- IR 시스템에서 이루어지는 기술은 크게 Indexing / Matching 이라고 할 수 있다.
쿼리가 입력되었을 때의 프로세스
- Language Understanding : 쿼리의 의도 파악하고, 엔티티의 명확화 그리고 몇 가지 부족한 부분을 추가하는 방식으로 기타 세부 정보를 식별하고 처리
- Language Generation : 자동완성, 스펠 체크, 쿼리를 제안하여 언어생성 등의 과정을 거침
- Doc Retrieval & Ranking : 여러 개의 문서에서 검색하고 그 중에 중요한 것(사용자의 클릭률 등)의 순위를 메겨서 계산
2. 추천 시스템 (Recommender system)
- 현대의 e-commerce / 온라인 쇼핑 등에서 필수적 요소
- 개인의 (암묵적) 요구/수요/취향에 맞춘 제안
- 자연어 처리 기반의 추천 시스템 중 '컨텐츠 기반 추천 시스템'
- 컨텐츠 기반 필터링 : 텍스트에 기반하여 문서 *유사도를 측정해 비슷한 다른 컨텐츠를 추천하는 것
- *유사도 : 텍스트를 벡터화 시킨 후 벡터들 간의 거리를 측정하는 것
ex) 코사인 유사도의 사용

- 컨텐츠 기반 추천 시스템의 프로세스
- 컨텐츠에 대한 내용의 텍스트를 BOW(Bag Of Words) 또는 Word Embedding 방식으로 Feature Vecotrization 시킨다.
- 컨텐츠들의 Feature 벡터들 간에 Distance function(여기서는 Cosine Similarity를 사용)을 사용해서 유사도 행렬을 구해준다.
- 유사도 행렬과는 별개로 또 다른 파생변수로 컨텐츠에 대한 고객들의 평점개수와 평점을 이용해 가중 평점을 계산 (파생 변수는 컨텐츠 성격에 맞게 유동적으로 변경 가능)
- 특정 컨텐츠를 기준으로 그 컨텐츠와 유사도, 가중평점이 가장 높은 순으로 정렬한 후 컨텐츠를 추천해 준다.
가중평점 공식

3. 감성 분석 (Sentiment analysis)
- 소셜 미디어 (Social media) 등 대중의 언어로 표현되는 감정에 대한 분류 / 추출
- 관용적/함축적 표현을 통하여 언어를 활용한 감정 표현을 수행
- 텍스트에 들어있는 의견이나 감성, 평가, 태도 등의 주관적인 정보를 컴퓨터를 통해 분석하는 과정
- 언어의 모호성은 감성 분석을 어렵게 한다.
예를 들어, "Genesis GV70 and G80 are nice cars" 라는 문장은 제네시스의 차종에 대한 긍정적인 평가를 가지고 있다고 볼 수 있지만, 같은 문장에 "Genesis GV70 and G80 are nice cars but hardly the best car on the road" 하지만 도로에서 가장 좋은 차는 아니다. 라는 문장이 붙음으로써 제네시스에 대한 평가가 긍정적인지 부정적인지 모호해지게 된다.
감성 분석 순서도

감성 분석 프로세스
- 감성 분석은 크게 어휘 기반(Lexicon-based) 감성 분석과 머신러닝 기반(ML-based) 감성 분석으로 나눠진다.
(1) 어휘 기반(Lexicon-based) 감성 분석
- Manual (수동적)
- 감성 사전을 수동적으로 구현
- *감성 사전 : 문서의 각 단어가 가지는 긍/부정의 정도를 -1(부정) 부터 1(긍정) 사이의 점수로 레이블링한 것
- 감성이 들어갈 수 있는 품사인 명사, 형용사, 동사 키워드를 추출한 뒤에 이들에 대한 긍/부정 레이블링을 진행
- 연관어 분석을 통해서 어떤 단어가 해당하는 단어들과 같이 사용되었는지도 알 수 있다.
- 장점 : 한 번 수행하고나면 적용하기 쉽다.
- 단점 : 도메인에 따라 사용하는 어휘가 달라지고 긍/부정 점수도 달라질 수 있기 때문에 모든 도메인에 적용할 수 있는 감성 사전을 구축하는 것이 매우 어렵다.
- Dictionary-based (사전 기반)
- 매 분석마다 새로운 사전을 쓰는 것이 아니라 기존에 잘 구축되어 있는 외부 사전을 차용
- 도메인 확장성이 없다.
예를 들어, 영화 리뷰 데이터에서의 '졸리다'는 부정적인 의미를 가지고 있지만, 침대 상품평 데이터에서의 '졸리다'는 긍정적인 의미를 가지고 있다. 이렇게 도메인에 따라 단어가 다르게 해석될 수 있으므로 사용하고 있는 사전과 사전을 적용하려는 데이터가 다른 도메인을 가지고 있다면 정확한 분석을 하기 어렵다.
- Corpus-based (말뭉치 기반)
- 도메인 의존성을 극복할 수 있지만 좋은 사전 구축을 위해서 많은 데이터(거대한 말뭉치)를 필요로 한다.
- 특정 말뭉치를 분석하는 경우에는 해당 단어가 사용되었을 때 문장의 긍/부정을 t-Test를 통해서 판단
(2) 머신러닝 기반(ML-based)의 감성 분석
- Linear (선형 회귀분석)
- 일반적으로 리뷰 데이터에는 평점을 부여하는데, 이렇게 평점을 레이블링 된 데이터에 회귀 분석 모델을 적용하여 각 단어에 대한 감성 사전을 구축
- 구축한 이후에는 교차 검증을 통해 감성 사전으로서의 타당한 성능을 지니는지를 평가
- 검증을 통해 구축한 사전의 성능이 확보된 후에는 새로운 문서에 대한 감성 분석을 수행
- Semi-supervied (준지도 학습)
- 준지도 학습을 통한 감성 분석은 감성 그래프(Sentiment graph)를 이용하는 방식과 자가 학습(Self-training) 두 가지로 나누어 진다.
- 감성 그래프(Sentiment graph) : 고차원 단어를 저차원으로 임베딩한 후에 거리를 기반으로 각 단어 사이의 네트워크를 구축 -> 감성 점수가 확실한 수 개의 단어를 미리 레이블링(Pre-labeled sentiment words)한 뒤에 공간상의 위치에 따라 나머지 단어의 감성 점수를 측정
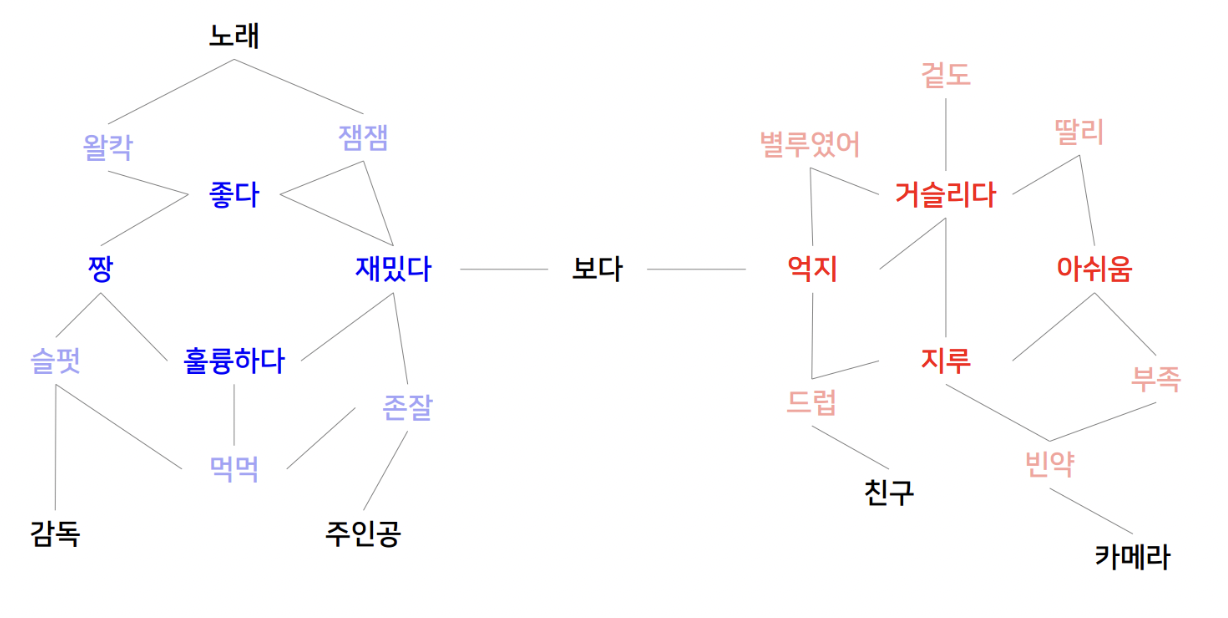
- 자가 학습(Self-training) : 이 방법 역시 감성 그래프 방법에서 했던 것과 같이 특정한 수 개의 단어는 미리 레이블링 되어 있다. 이 어휘로만 분류기를 학습한 뒤에 정답이 없는 어휘에 분류기를 적용하여 결과의 신뢰도가 높으면 정답으로 지정한 후에 학습기를 재학습하는 방식

4. 생물정보학 (Bioinformatics)
- 유전체(Genome)의 염기(ATGC) 서열 분석
