[NLP] 정규 표현식 (Regular Expressions)
🎯텍스트 처리
- 텍스트로부터 고품질의 정보를 유도하기 위해 필요한 작업
- 텍스트를 가공해서 표준화 된 + 계산 가능한 + 유용한 형태로 변환하는 것 (전처리도 포함)
ex) Tokenization
- 본질의 의미는 같지만 활용 형태가 다른 단어가 존재
ex) woodchuck = woodchucks = Woodchuck = Woodchucks = ...
- 텍스트 처리를 텍스트 분석으로 보는 시각
: 활용 형태가 다른 텍스트 샘플들로부터 패턴을 인식하여 tokenization을 수행
ex) 공백을 활용한 단어의 분리, 단어의 어근을 활용한 정규화 등
🎯 텍스트 정규화
: 텍스트를 이전에 없던 단일 표준 형식으로 변환하는 과정
(1) tokenization (토큰화) 작업
- 텍스트에서 단어를 분리하고 토큰화하는 작업
(2) lemmatization (분류화) 작업
- 같은 형태의 뜻을 가지고 있는지 분류
ex) sang, sung, sing -> sing
(3) edit distance 작업
- 단어와 문장을 비교
- 두 문장이 문장 구조나 특징들에 기반하여 얼마나 유사한지 비교
🎯 정규표현식 (Regular expressions) = Regex, Regexp

- 특정 규칙을 가진 문자열의 집합을 표현하기 위한 형식 언어
- 자연어를 처리함에 있어서, 기계가 자연어를 파악하도록 만들기 위해 쓰는 도구 중 하나이다.
Basic Regular Expression Patterns
- 정규화 표현의 가장 간단한 종류는 간단한 문자열

- Divider 기호 / 를 가진 expression은 Divider 앞 뒤를 기준으로 어떠한 문자가 와도 상관없다는 뜻을 의미
- Case sensitive
- 정규표현식에서는 대소문자를 구분한다.
- 따라서 a와 A가 있는 문자열을 모두 검색하고 싶다면 [] 중괄호를 이용
ex) /[aA]/ , /[wW]oodchuck/
- Disjunctions - Brackets []
- [] 중괄호에 있는 문자들은 or과 같은 뜻을 가지고 있다.

- Disjunctions - Ranges - (minus)
- 모든 숫자 검색 : /[0-9]/
- 모든 알파벳 검색 : /[A-Za-z]/

- Negation ^
- [] 내에서 첫 번째 부호로 쓰이는 ^
- 그 외의 위치에는 본래의 용도로 쓰임

- Wildcards - Question mark ? (복수형)
- ? 직전 문자에 대한 선택적인 매치
- 즉, 바로 앞에 문자가 있어도 되고, 없어도 되는 식을 찾는 것
ex) 개미에 대한 정보가 필요하다면 ant, ants 상관없이 개미를 뜻하는 단어만 검색하면 된다.
-> /ants?/ 로 검색 -> ant or ants

ex)
/woodchucks?/ -> woodchucks or woodchuck
/colou?r/ -> color or colour
- Counters - Asterisk *
- * 직전 문자에 대한 선택적인 매치 혹은 다수 매치 (0번 이상)
- 즉, 반복적으로 나타나는 문자를 검색하고 싶을 때
ex) /baaa*!/ -> baa! , baaa!, baaaa!, baaaaa! ... ba!(불가능)
/[ab]*/ -> a나 b가 0번이나 그 이상의 빈도수만큼 나타나는 문자열을 찾는 것
- Counters - Plus +
- + 직전 문자에 대한 단일 매치 혹은 다수 매치 (1번 이상)
- 즉, +앞에 있는 문자를 적어도 한 번은 포함하는 문자열을 찾는 것
- Wildcards - Point .
- .은 모든 문자와 매치 가능
- 모든 문자열 중에 아무거나 와도 된다.

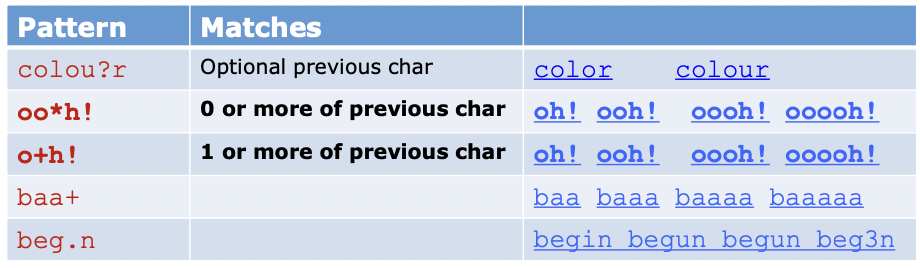
📌 사용 예시
- [ab]* -> a 혹은 b의 연속적인 출현
- [0-9][0-9]* -> 숫자 하나로 시작하고, 연속적인 숫자의 출현도 가능 , [0-9]+ 와 같은 의미
- aardvark.*aardvark -> aardvark라는 문자열의 두번 출현 (두번의 출현 사이에 어떤 문자열이 오든 관계 없음)]
-> *의 직전문자는 .이므로 .에 대해 0번 이상 존재하므로 맨 앞의 aardvark는 항상 있어야한다.
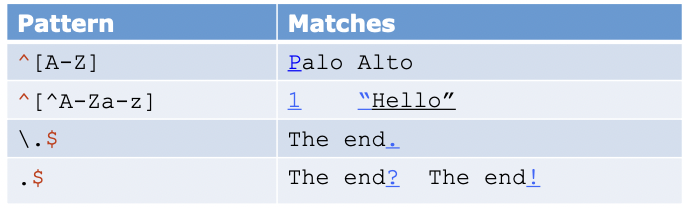
- Anchors (패턴의 시작과 끝을 가리키는 문자)
| ^ | 패턴의 시작 | ^The dog\.$ 매치되는 패턴 : The dog. 여기서 사용된 역슬래쉬는 .을 모든 문자(wildcard)가 아닌 특수문자 . 으로 표현하기 위함 |
| $ | 패턴의 끝 | \bthe\b 매치되는 패턴 : the 매치되지 않는 패턴 : other |
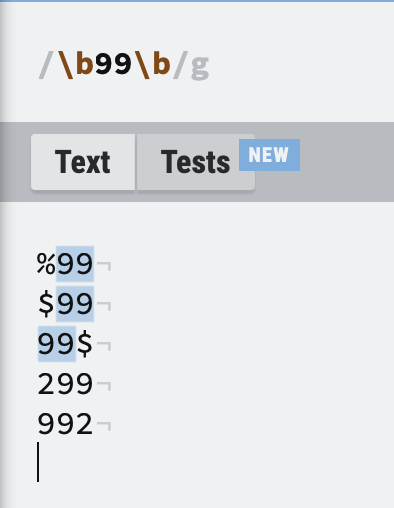
| \b | 단어의 범위 문자열의 시작과 끝의 위치를 일치 시킨다 |
\b99\b 매치되는 패턴 : 99, $99 매치되지 않는 패턴 : 299 |
| ^dog\.$ | \. : Matches a "." character 역슬래쉬가 먼저 나오고 .이 나오는 경우 .은 특수문자 취급 $ : Matches the end of the string, or the end of line if the multiline flag is enabled |
| ^dog.\$ | . : Matches any character expect line breaks \$ : Matches a "$" character |
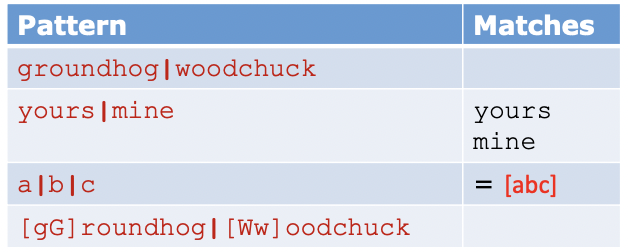
- More Disjunctions - Pipe |
- 문자열에 대한 선택
- | 로 구분된 다수 문자열 간의 선택
* 정규표현식에서 or과 같은 표현을 하고 싶을때, []와 같은 중괄호를 사용한다. 하지만 중괄호의 경우 하나의 문자에 해당한다는 것이고, 복수의 문자를 or로 표현할 수는 없다. 따라서 복수의 문자를 or로 표현한기 위해서는 '|' 파이프 기호가 필요하다.
ex) cat이나 dog가 포함된 문자열을 찾을 경우 -> /cat|dog/
- More Disjunctions - Parenthesis () 괄호
- 특정 패턴에만 적용하는 disjunction을 위해서 사용
- * 또는 +를 직전 문자가 아닌 직전 패턴에 적용하고 싶은 경우 유용
- ( 와 ) 사이에 있는 문자열을 단일 문자 (single character)로 간주하도록 함
ex) guppy의 복수형은 guppies이다. 만약 guppy와 관련된 정보를 찾고 싶을 때에는 ?
-> /gupp(y | ies)/
ex) Column 1 Column 2 Column
와 같이 Column에 숫자가 이어지는 패턴의 반복 매치 (숫자 뒤 공백의 길이는 가변)
-> /(Column [0-9]+ *)*/
= Column + 공백 한칸 + 숫자 다됨 + 공백 길이 무관 + Column + 공백 한칸 + 숫자 다됨 + 공백 길이 무관 + ...
-> /Column [0-9]+ */
= 하나의 Column 만 매치 가능
= Column + 공백 한칸 + 숫자 다됨 + 공백 길이 무관 <끝>
- 괄호는 operator precedence hierarchy를 결정하는 데도 사용된다.

ex) the* -> theeee : 매치 가능 , thethe : 매치 불가능
- 이외의 정규 표현식
- 일반적으로 정규표현식은 Greedy 매치를 강제
- 즉, 가능한 가장 긴 패턴을 매치
ex) [a-z]*
once up a time과 매치될 수도 있고,
o과 매치될 수도 있고,
on과 매치될 수도 있고,
....
- 따라서 Greedy match를 회피하기 위해서 ? 를 사용
ex) [a-z]*? -> 가장 짧은 텍스트 패턴과 매치된다.
- 예약어

- Counters

- with backslash
