
티스토리 뷰
🎯 Machine Learning 이란?
인공지능의 하위 집합으로, 학습과 개선을 위해 명시적으로 컴퓨터를 프로그래밍하는 대신, 컴퓨터가 데이터로 학습하고 경험을 통해 개선하도록 훈련하는 학습
예를 들어, 전통적인 프로그래밍 방식에서는 강아지를 인식할 수 있는 프로그램을 작성하지만,
머신러닝에서는 단순히 많은 수의 동물 사진을 제공하며 어떤 사진이 강아지인지 알려주므로 머신러닝 시스템 스스로 사진에서 강아지를 인식할 수 있도록 만드는 것이다.

🎯 머신러닝의 종류
1. 지도 학습 (Supervised Learning)

- 컴퓨터는 예제(sample)와 정답(label)을 제공받는다.
- 지도 학습의 목표는 입력을 출력에 매핑하는 일반적인 규칙(함수, 패턴)을 학습하는 것이다.
- 예를 들어, 강아지와 고양이를 구분하는 문제라면 강아지와 고양이에 대한 사진을 제공한 후, 교사가 어떤 사진이 강아지인지, 고양이인지를 알려주는 것이다.
- 지도학습의 방식에는 크게 회귀(regression), 분류(classification)이 존재한다.
| 회귀 (regression) | 분류 (classification) |
| - 주어진 입력(x)-출력(y) 쌍을 학습한 후에 새로운 입력값이 들어왔을 때, 합리적인 출력값을 예측하는 것 - 회귀에서는 학습시키는 데이터가 이산적이 아니라 연속적이다. (즉, 입력과 출력이 모두 실수) - 회귀 모델은 연속적인 값을 예측 ex) 운동을 하루 5시간 한다면 그 사람의 예측 수명은 어떻게 될까? |
- 입력을 두 개 이상의 레이블(유형)로 분할하는 것 - 따라서 올바른 레이블을 제공해야 한다. - 학습이 끝나면 학습자가 한 번도 보지 못한 입력을 이들 레이블 중의 하나로 분류하는 시스템 - y=f(x)에서 출력 y가 이산적(discrete)인 경우 - 신경망, kNN, SVM, 의사 결정 트리 등이 포함 |
2. 비지도 학습 (Unsupervised Learning)

- 외부에서 정답(label)이 주어지지 않고 학습 알고리즘이 스스로 입력 데이터에서 어떤 패턴을 발견하는 학습
- ex) 과일의 모양, 색상, 크기 등 다양한 특징을 이용해 유사한 과일들을 분류
- y=f(x)에서 레이블 y가 주어지지 않는 것
- 데이터들의 상관도를 분석하여 유사한 데이터들을 모을 수 있다.
3. 강화 학습 (Reinforcement Learning)

- 보상 및 처벌의 형태로 학습 데이터가 주어진다.
- 주로 차량 운전이나 상대방과의 경기 같은 동적인 피드백만 제공되는 경우
- ex) 바둑에서 어떤 수를 두어서 승리하였다면 보상이 주어진다.
4. 자기지도 학습 (self supervised learning)
- 최근 가장 많이 사용하고 있는 학습방법
- label이 없는 untagged data를 기반으로 한 학습이며 자기 스스로 학습 데이터에 대한 분류를 수행
🎯 머신러닝 과정
1. 학습 데이터 모으기
2. 학습 데이터 정제하기
3. 모델 학습하기
4. 평가
5. 예측
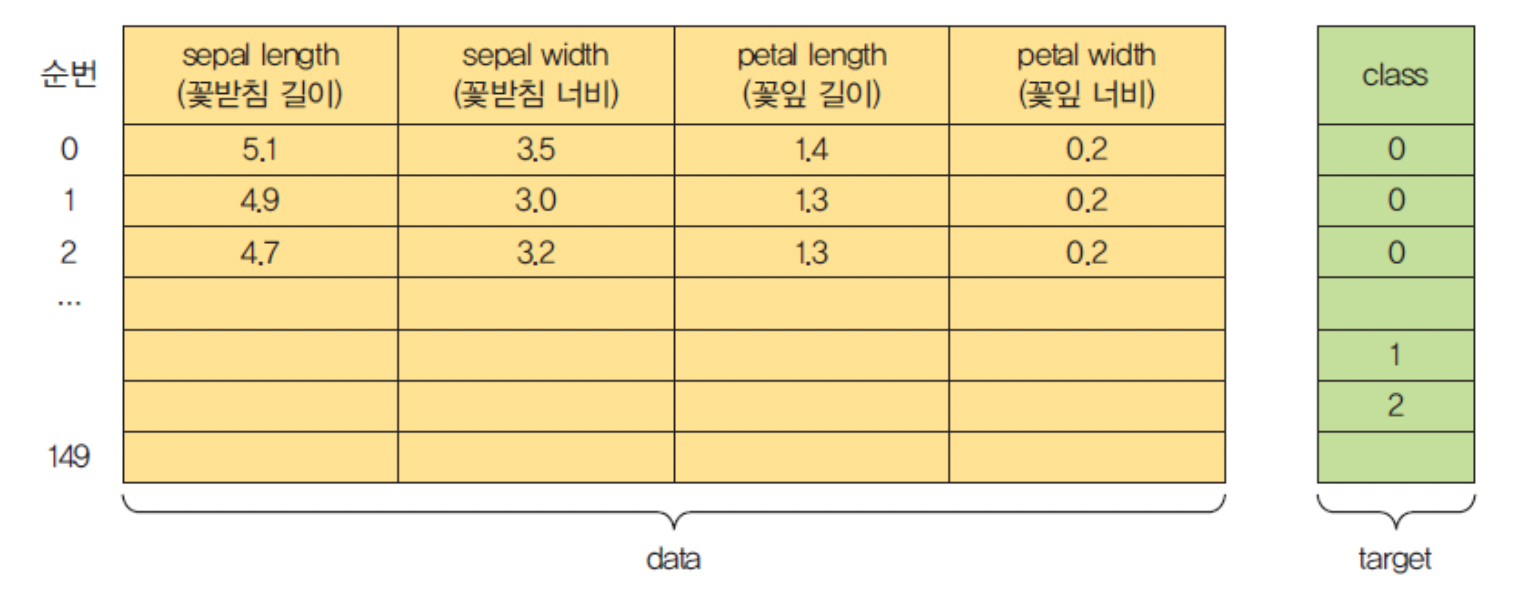
예시 1) 붓꽃 데이터 세트 분류 (iris)
1. 데이터 가져오기
from sklearn import datasets
iris = datasets.load_iris( )
print(iris)
2. 훈련 데이터와 테스트 데이터 분리
from sklearn.model_selection import train_test_split
X = iris.data
y = iris.target
# (80:20)으로 분할
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=4)
print(X_train.shape)
print(X_test.shape)
3. 모델 선택
- k-Nearest Neighbor(kNN) 알고리즘은 모든 머신러닝 알고리즘 중에서도 가장 간단하고 이해하기 쉬운 분류 알고리즘
k-NN 알고리즘은 데이터로부터 거리가 가까운 'k'개의 다른 데이터의 레이블을 참조하여 분류하는 알고리즘

4. 학습
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=6)
knn.fit(X_train, y_train)
5. 평가
y_pred = knn.predict(X_test)
from sklearn import metrics
scores = metrics.accuracy_score(y_test, y_pred)
print(scores)
6. 예측
classes = {0:'setosa',1:'versicolor',2:'virginica'}
# 전혀 보지 못한 새로운 데이터를 제시해보자.
x_new = [[3,4,5,2], [5,4,2,2]]
y_predict = knn.predict(x_new)
print(classes[y_predict[0]])
print(classes[y_predict[1]])
예시 2) 필기체 숫자 분류 (MNIST)

1. 데이터 세트 읽기
import matplotlib.pyplot as plt
from sklearn import datasets, metrics
from sklearn.model_selection import train_test_split
digits = datasets.load_digits()
plt.imshow(digits.images[0], cmap=plt.cm.gray_r, interpolation='nearest')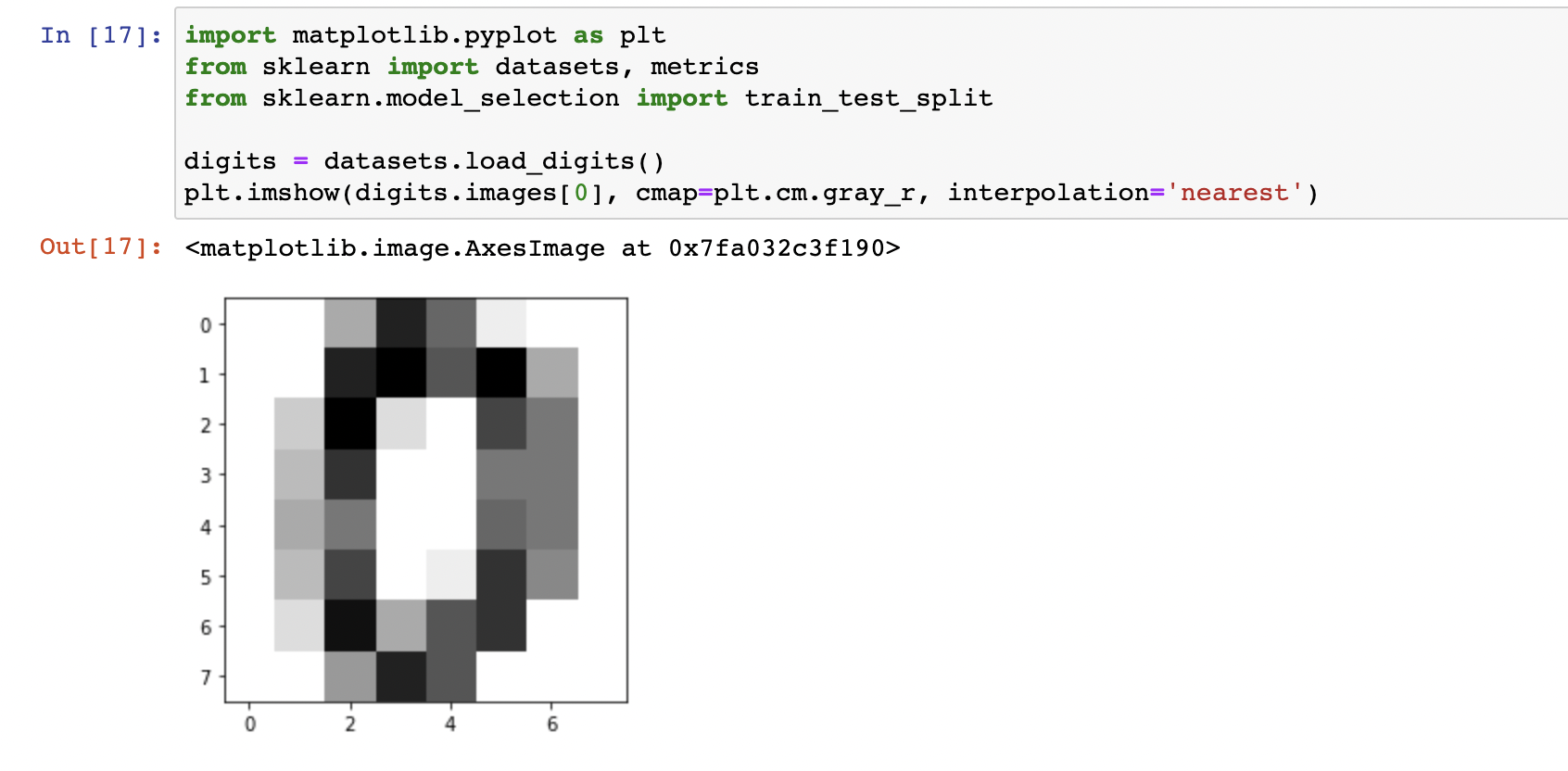
import matplotlib.pyplot as plt
from sklearn import datasets, metrics
from sklearn.model_selection import train_test_split
digits = datasets.load_digits()
plt.imshow(digits.images[9], cmap=plt.cm.gray_r, interpolation='nearest')
2. 이미지 평탄화 (flatten)
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
3. 훈련 데이터와 테스트 데이터 분류
# 80:20 비율로 데이터 나누기
X_train, X_test, y_train, y_test = train_test_split( data, digits.target, test_size=0.2)
4. 모델과 학습
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=6)
knn.fit(X_train, y_train)
5. 예측
# 테스트 데이터로 예측
y_pred = knn.predict(X_test)
# 정확도를 계산
scores = metrics.accuracy_score(y_test, y_pred)
print(scores)
# 이미지를 출력하기 위하여 평탄화된 이미지를 다시 8×8 형상으로 만 든다.
plt.imshow(X_test[10].reshape(8,8), cmap=plt.cm.gray_r, interpolation='nearest')
y_pred = knn.predict([X_test[10]])
# 입력은 항상 2차원 행렬이어야 한다.
print(y_pred)
🎯 혼동 행렬
| TP (True Positive) | 긍정을 긍정으로 올바르게 예측 |
| FN (False Negative) | 긍정을 부정으로 잘못 예측 |
| FP (False Positive) | 부정을 긍정으로 잘못 예측 |
| TN (True Negative) | 부정을 부정으로 올바르게 예측 |
import matplotlib.pyplot as plt
from sklearn import datasets, metrics
from sklearn.model_selection import train_test_split
digits = datasets.load_digits()
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=6)
X_train, X_test, y_train, y_test = train_test_split( data, digits.target, test_size=0.2)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
disp = metrics.plot_confusion_matrix(knn, X_test, y_test)
plt.show()

성능 척도

ex)
민감도 : 질병이 있는 사람을 환자라고 올바르게 진단하는 비율
특이도 : 질병이 없는 사람을 환자가 아니라고 올바르게 진단하는 비율
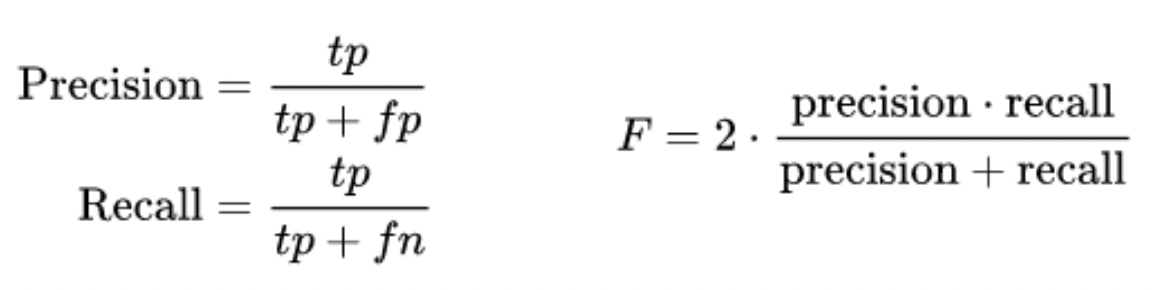
'🚀 What I Studied > AI' 카테고리의 다른 글
| [AI] KERAS (0) | 2022.10.29 |
|---|---|
| [AI] Perceptron (0) | 2022.10.28 |
| [AI] Linear Regression (0) | 2022.10.27 |