
 [Statistics] 데이터 시각화와 통계적 해석
[Statistics] 데이터 시각화와 통계적 해석
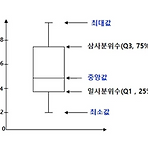
데이터사이언스를 위한 통계학입문Ⅰ https://pabi.smartlearn.io/courses/course-v1:POSTECH+DSB111+P2203/about 데이터사이언스를 위한 통계학입문Ⅰ pabi.smartlearn.io III. 데이터 시각화와 통계적 해석 3.1 데이터 시각화 데이터 시각화 : 데이터 분석 결과를 쉽게 이해할 수 있도록 보여주는 것 데이터 분석 단계 수집 (Data Gathering) 정제 (Data Processing) 시각화 (Data Visualization) 예측모형/분석 (Data Analysis) 효과적인 데이터 시각화의 조건 어떤 메세지를 전달할 것인지 결정 (what) 핵심 내용을 제외한 나머지는 생략 최선의 표현 방법을 선택 (How) 단순, 명료하게 디자인 ..
 [Algorithm] 해시를 사용한 집합(set)과 맵(map)
[Algorithm] 해시를 사용한 집합(set)과 맵(map)
🌵 Hash Function (해시 함수) 또는 Hash Algorithm (해시 알고리즘) 임의의 길이의 데이터(key)를 고정된 길이의 데이터(hash)로 매핑하는 함수 이 과정을 hashing이라 한다. 즉, 해시 함수 : key (Input) -> Hash (Output) 이때의 Hash는 저장 위치가 된다. 🌵 Hash Table (해시 테이블) 또는 Hash Map (해시 맵) 해시값을 주소 또는 색인 삼아 데이터(value)를 key와 함께 저장하는 자료구조이다. 파이썬의 딕셔너리(dictionary) 자료형은 해시 테이블로 구현되어 있다. 장점 해시 테이블은 key-value가 1:1로 매핑되어 있기 때문에 삽입, 삭제, 검색의 과정에서 모두 평균적으로 O(1)의 시간 복잡도를 가지고 있다..
 [Statistics] 빅데이터 탐색의 첫걸음
[Statistics] 빅데이터 탐색의 첫걸음
데이터사이언스를 위한 통계학입문Ⅰ https://pabi.smartlearn.io/courses/course-v1:POSTECH+DSB111+P2203/about 데이터사이언스를 위한 통계학입문Ⅰ pabi.smartlearn.io II. 빅데이터 탐색의 첫걸음 2.1 데이터의 평균 (중심위치) 평균 - 데이터를 하나의 값으로 표현한 요약된 정보 (추정치) - 평균 = 데이터 값의 총 합 / 데이터 개수 평균을 다룰 때 주의할 점 - 평균은 혼자 존재하는 개념이 아니다. - 어떻게 표본선정을 하느냐에 때라 평균값에 영향을 미친다. 따라서 조사된 평균값이 모집단을 대표하는 통계치라고 할 수 있는지에 대한 고려가 필요 평균과 표본 산정 1. 편의 (Bias)가 적은가? - 표본을 추출할 때 표본으로부터 얻어지..
 [Python] ⭐️백준 알고리즘 1018번 : 체스판 다시 칠하기
[Python] ⭐️백준 알고리즘 1018번 : 체스판 다시 칠하기
https://www.acmicpc.net/problem/1018 1018번: 체스판 다시 칠하기 첫째 줄에 N과 M이 주어진다. N과 M은 8보다 크거나 같고, 50보다 작거나 같은 자연수이다. 둘째 줄부터 N개의 줄에는 보드의 각 행의 상태가 주어진다. B는 검은색이며, W는 흰색이다. www.acmicpc.net 👩💻문제 이해 브루트포스 알고리즘을 이용해 주어진 배열을 모두 돌며 다시 칠해야하는 부분을 카운트하고 최소값을 찾는다. 맨 위 왼쪽 체스판이 흰색인 경우, 검은색인 경우로 나누어 다시 칠해야 하는 수를 확인 해야한다. 👩💻반복문을 사용해 모든 경우 체크 : 성공🌈 n, m=map(int,input().split()) # n행, m열 arr = [] cnt=[] for i in range..
 [Python] 백준 알고리즘 11478번 : 서로 다른 부분 문자열의 개수
[Python] 백준 알고리즘 11478번 : 서로 다른 부분 문자열의 개수
https://www.acmicpc.net/problem/11478 11478번: 서로 다른 부분 문자열의 개수 첫째 줄에 문자열 S가 주어진다. S는 알파벳 소문자로만 이루어져 있고, 길이는 1,000 이하이다. www.acmicpc.net 👩💻문제 이해 중복되는 값은 허용하지 않기 때문에 set 자료형을 사용한다. 👩💻set() 자료형과 반복문 사용 : 성공🌈 s = input() res = set() for i in range(len(s)): res.add(s[i]) res.add(s) for i in range(1, len(s)-1): for j in range(len(s)-i): res.add(s[j:j+i+1]) print(len(res)) s = input() res = set() for..
 [Python] 백준 알고리즘 1920번 : 수 찾기
[Python] 백준 알고리즘 1920번 : 수 찾기
https://www.acmicpc.net/problem/1920 1920번: 수 찾기 첫째 줄에 자연수 N(1 ≤ N ≤ 100,000)이 주어진다. 다음 줄에는 N개의 정수 A[1], A[2], …, A[N]이 주어진다. 다음 줄에는 M(1 ≤ M ≤ 100,000)이 주어진다. 다음 줄에는 M개의 수들이 주어지는데, 이 수들 www.acmicpc.net 👩💻문제 이해 list를 이용해 각각의 원소들을 비교하면 쉽게 풀릴 문제지만, 시간초과가 난다. 따라서 처음 주어지는 배열을 오름차순으로 정렬해 이분 탐색 알고리즘을 이용해 풀었다. 👩💻List만 사용 : 시간초과💀 import sys n = int(input()) nli = sys.stdin.readline().split() m = int(in..